Author Archive
Presentations: Starting your security career – where can you go?
I gave a talk on career planning in Information Security at Abertay University on the 16th of January 2013.
Securi-Tay is an annual security conference organised by students at Abertay and is a very well organised and run event – could put some professional conferences to shame!
The talk went down very well, with a lot of discussion spinning off afterwards, and the odd additional visitor to Sec.SE
Most of the video should be straightforward, but a couple of the slides may be hard to read so I have included them here:
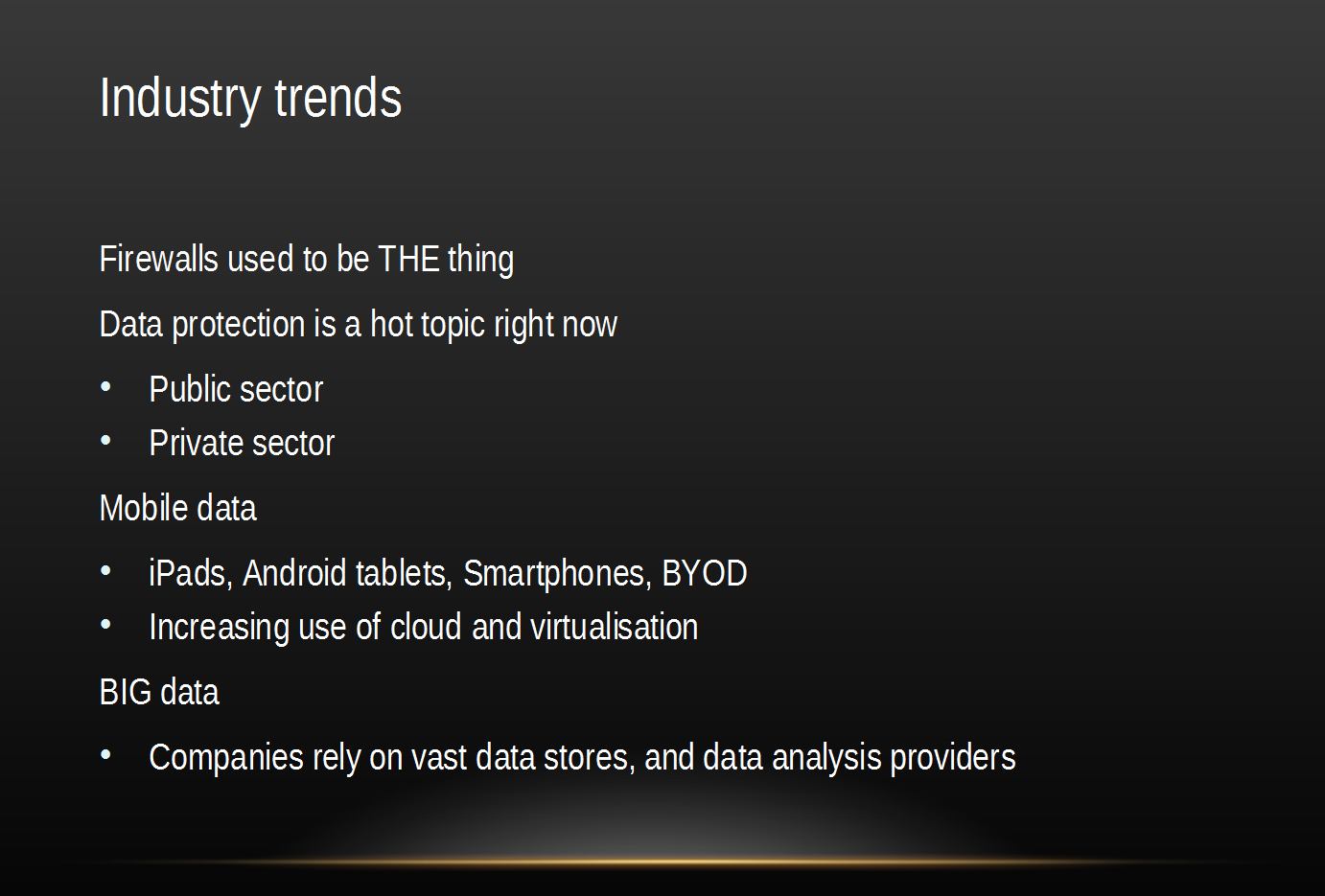
Slide 8, industry trends:
Slide 13, some useful certifications:

Slide 14, the time-bounded nature of certifications:
Slide 16, self marketing (see that nice big Sec.SE logo:-):
QoTW #44: How to block or detect user setting up their own personal wifi AP in our LAN?
Nominated by Terry Chia, this question by User15580 should be of interest to anyone managing the security of network s.
The show the variety of aspects security covers in this sort of scenario:
Daniel posted the top answer, and it has nothing to do with IT, but instead focuses on the cause – if a user has installed an access point it is because they need something the existing network is not providing. This is always worth considering:
Discuss with the users what they are trying to accomplish. Perhaps create an official wifi network ( use all the security methods you wish – it will be ‘yours’ ). Or, better, two – Guest and Corporate WAPs.
Polynomial and Thomas Pornin also highlighted the fact this is a user/managerial problem, rather than a technical one.
Remember Immutable Law of Security #10: Technology is not a panacea. Whilst technology can do some amazing things, it can’t enforce user behaviour. You have a user that is bringing undue risk to the organisation, and that risk needs to be dealt with. The solution to your problem is _policy_, not technology. Set up a security policy that details explicitly disallowed behaviours, and have your users sign it. If they violate that policy, you can go to your superiors with evidence of the violation and a penalty can be enforced. As long as the users have physical access to the machines they use and their USB ports (that’s hard to avoid, unless you pour glue in all the USB ports…) and that the installed operating systems allow it (then again, hard to avoid if users are “administrators” on their systems, in particular in BYOD contexts), then the users can setup custom access points which gives access to, at least, their machine.
Rory McCune provided some information on the types of solutions which generally are used in large corporates, where they work well, including NAC and port lockdowns. Lie Ryan‘s comments tend to be appropriate on smaller networks.
k1DBLITZ also focuses on the use of technical solutions in addition to policy, and JasperWallace recommends looking for and blocking unapproved MAC addresses, and further answers discuss wireless scanning and scripted checks.
Overall, it would seem that a mixture of technical and management controls are required – the balance depending on your specific environment.
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
QoTW #42: Would publishing a network diagram make the network less secure?
I chose this week’s Question of the Week, saber tabatabaee yazdi‘s “Would publishing a network diagram make the network less secure?” because this is a point which seems to be often misunderstood.
Saber asked this question because he had come across various websites designed to let people share their network diagrams and designs in order that others can comment on them and provide guidance and he wondered what the risks would be from this.
As an example, this diagram from www.ratemynetworkdiagram.com provides IP addresses, host names and even descriptions:
AJ Henderson provided the very valid comment that security through obscurity is not security, but admits that any network will have some weaknesses, and avoiding giving this information to a potential attacker is probably advised.
My answer is taken from the experience of managing many hundreds of penetration tests. My take on it is:
having a map helps me target my attack, avoiding possible sensors, honeypots etc and aiming at high value targets or sources of information. This can speed up an attack immensely, reducing the defender’s chance of preventing it.
But the value from these sites is that you can have obvious mistakes pointed out to you – peer review can be a very valuable thing. So how can you do that safely?
To reduce risk, some steps you can take are:
- remove addresses, function titles etc
- only include sections of the network
- post under an anonymous profile
- include fake network sections
An attacker will still get information, but it hopefully won’t be enough to let them navigate your entire network.
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
Securi-Tay 2 Conference
Spent January 16th up in Dundee, at the University of Abertay, at Securi-Tay 2. It was a very well run conference – it was organised by students on the Ethical Hacking and Countermeasures course, but was better organised than some professional conferences I have been to.
I saw some excellent speakers, and gave a talk on career planning in information security, so mine was by far the least technical talk there.
Highlights for me:
- Rory McCune gave an excellent talk on automation of security testing, both as a standard practice to make life easier, but to help consistency and standards in testing.

- Marion McCune presented on using the Windows Surface for security testing, which I think surprised everyone with the power of an ARM powered tablet.

- Graham Sutherland’s talk on attacking office hardware ranged from simple and relatively harmless, to pretty hardcore hacking via chip removal and analysis. Excellent fun, but sadly there was no party hat…

- Nick Walker’s talk on Android Security Assessments, while slightly too technical for me, was very interesting, and reminded me to pop Cyanogenmod on my Galaxy S3 this weekend.
- The” Rory track” – of the two lecture theatres, one had 3 Rorys presenting, which just goes to confirm one of the Memes of Meta…
And the good folks at Securi-Tay kindly donated this bright red t-shirt to my con swag collection, so I went home even happier!

QoTW #41: Why do we lock our computers?
Iszi chose this week’s question of the week, Tom Marthenal‘s “Why do we lock our computers?” – as Tom puts it:
It’s common knowledge that if somebody has physical access to your machine they can do whatever they want with it, so what is the point?
This one attracted a lot of views, as it is a simple question of interest to everyone.
Both Bruce Ediger and Polynomial answered with the core reason – it removes the risk from the casual attacker while costing the user next to nothing! This is an essential factor in cost/usability tradeoffs for security. From Bruce:
The value of locking is somewhat larger than the price of locking it. Sort of like how in good neighborhoods, you don’t need to lock your front door. In most neighborhoods, you do lock your front door, but anyone with a hammer, a large rock or a brick could get in through the windows.
and from Polynomial:
An attacker with a short window of opportunity (e.g. whilst you’re out getting coffee) must be prevented at minimum cost to you as a user, in such a way that makes it non-trivial to bypass under tight time constraints.
Kaz pointed out another essential point, traceability:
If you don’t lock, it is easy for someone to poke around inside your session in such a way that you will not notice it when you return to your machine.
And zzzzBov added this in a comment:
…few bystanders would question someone walking up to a house and entering through the front door. The assumption is that the person entering it has a reason to. If a bystander watches someone break into a window, they’re much more likely to call the authorities. This is analogous with sitting down at a computer that’s unlocked, vs physically hacking into the system after crawling under a desk.
It removes a large percentage of possible attacks – those from your co-workers wanting to mess with your stuff – thanks enedene.
So – protect yourself from co-workers, casual snooping and pilfering and other mischief by simply locking your machine every time you leave your desk!
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
QoTW #40: What’s the impact of disclosing the front-face of a credit or debit card?
” What is the impact of disclosing the front face of a credit card?” and “How does Amazon bill me without the CVC/CVV/CVV2?” are two questions which worry a lot of people, especially those who are aware of the security risks of disclosing information, but who don’t fully understand them.
Rory McCune‘s question was inspired by a number of occasions where someone was called out for disclosing the front of their credit card – and he wondered what the likely impact of disclosing this information could be, as the front of the card gives the card PAN (16-digit number), start date, expiry date and cardholder name. Also for debit cards, the cardholders account number and sort code (that may vary by region).
TC1 asked how Amazon and other individuals can bill you without the CVV (the special number on the back of the card)
atdre‘s answer on that second question states that for Amazon:
The only thing necessary to make a purchase is the card number, whether in number form or magnetic. You don’t even need the expiration date.
Ron Robinson also provides this answer:
Amazon pays a slightly higher rate to accept your payment without the CVV, but the CVV is not strictly required to present a transaction – everybody uses CVV because they get a lower rate if it is present (less risk, less cost).
So there is one rule for the Amazons out there and one rule for the rest of us. Which is good – this reduces the risk to us of card fraud. Certainly for online transactions.
So what about physical transactions – If I have a photo of the front of a credit card and use it to create a fake card, is that enough to commit fraud?
From Polynomial‘s answer:
On most EFTPOS systems, it’s possible to manually enter the card details. When a field is not present, the operator simply presses enter to skip, which is common with cards that don’t carry a start date. On these systems, it is trivial to charge a card without the CVV. When I worked in retail, we would frequently do this when the chip on a card wasn’t working and the CVV had rubbed off. In such cases, all that was needed was the card number and expiry date, with a signature on the receipt for verification.
So if a fraudster could fake a card it could be accepted in retail establishments, especially in countries that don’t yet use Chip and Pin.
Additionally, bushibytes pointed out the social engineering possibilities:
As a somewhat current example, see how Mat Honan got hacked last summer :http://www.wired.com/gadgetlab/2012/08/apple-amazon-mat-honan-hacking/all/ In his case, Apple only required the last digits for his credit card (which his attacker obtained from Amazon) in order to give up the account. It stands to reason that other vendors may be duped if an attacker were to provide a full credit card number including expiration dates.
In summary, there is a very real risk of not only financial fraud, but also social engineering, from the public disclosure of the front of your credit card. Online, the simplest fraud is through the big players like Amazon, who don’t need the CVV, and in the real world an attacker who can forge a card with just an image of the front of your card is likely to be able to use that card.
So take care of it – don’t divulge the number unless you have to!
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
QoTW #39: Why would a virus writer bother to check to see if a machine is infected before infecting it?
Terry Chia proposed Swaroop’s question from 2 October 2012: Why would a virus writer bother to check to see if a machine is infected before infecting it?
Swaroop was wondering if this would be an attempt to use files that are already present instead of transferring another copy to the machine, but actually it boils down to two main reasons – the malware writer wants the computer to remain stable for as long as possible, and there is competition between virus writers for control over your PC.
Polynomial wrote:
The less resources used and the less disturbance caused, the less likely the user is to notice something is wrong. Once a user notices something isn’t working properly, they’ll try to fix it, which might result in the malware being removed. As such, it’s better for the malware creator to prevent these problems and remain covert.
Thomas Pornin linked to the original internet worm, which did prevent networks and systems working because it didn’t carry out checks, and both Celeritas and OtisBoxcar supported Polynomial’s top answer with theirs.
WernerCD wrote:
Preemptive removal of competitors products, as well as verification of no prior version of my product, would help keep the system mine. As mentioned, the goal would be to keep the CPU “mine”. That means lay low and don’t attract notice.
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
QotW #36: How does the zero-day Internet Explorer vulnerability discovered in September 2012 work?
Community member Iszi nominated this week’s question, which asks for an explanation of the issue from the perspective of a developer/engineer: What is exactly being exploited and why does it work?
Polynomial provided the following detailed, technical answer:
CVE-2012-4969, aka the latest IE 0-day, is a based on a use-after-free bug in IE’s rendering engine. A use-after-free occurs when a dynamically allocated block of memory is used after it has been disposed of (i.e. freed). Such a bug can be exploited by creating a situation where an internal structure contains pointers to sensitive memory locations (e.g. the stack or executable heap blocks) in a way that causes the program to copy shellcode into an executable area.
In this case, the problem is with the CMshtmlEd::Exec function in mshtml.dll. The CMshtmlEd object is freed unexpectedly, then the Exec method is called on it after the free operation.
First, I’d like to cover some theory. If you already know how use-after-free works, then feel free to skip ahead.
At a low level, a class can be equated to a memory region that contains its state (e.g. fields, properties, internal variables, etc) and a set of functions that operate on it. The functions actually take a “hidden” parameter, which points to the memory region that contains the instance state.
For example (excuse my terrible pseudo-C++):
class Account
{
int balance = 0;
int transactionCount = 0;
void Account::AddBalance(int amount)
{
balance += amount;
transactionCount++;
}
void Account::SubtractBalance(int amount)
{
balance -= amount;
transactionCount++;
}
}
The above can actually be represented as the following:
private struct Account
{
int balance = 0;
int transactionCount = 0;
}
public void* Account_Create()
{
Account* account = (Account)malloc(sizeof(Account));
account->balance = 0;
account->transactionCount = 0;
return (void)account;
}
public void Account_Destroy(void* instance)
{
free(instance);
}
public void Account_AddBalance(void* instance, int amount)
{
((Account)instance)->balance += amount;
((Account)Account)->transactionCount++;
}
public void Account_SubtractBalance(void* instance, int amount)
{
((Account)instance)->balance -= amount;
((Account)instance)->transactionCount++;
}
public int Account_GetBalance(void* instance)
{
return ((Account)instance)->balance;
}
public int Account_GetTransactionCount(void instance)
{
return ((Account*)instance)->transactionCount;
}
I’m using void* to demonstrate the opaque nature of the reference, but that’s not really important. The point is that we don’t want anyone to be able to alter the Account struct manually, otherwise they could add money arbitrarily, or modify the balance without increasing the transaction counter.
Now, imagine we do something like this:
Account_Destroy(myAccount); // ...void* myAccount = Account_Create(); Account_AddBalance(myAccount, 100); Account_SubtractBalance(myAccount, 75); // ... if(Account_GetBalance(myAccount) > 1000) // <-- !!! use after free !!! ApproveLoan();Now, by the time we reach
Account_GetBalance, the pointer value in myAccount actually points to memory that is in an indeterminate state. Now, imagine we can do the following:
- Trigger the call to
Account_Destroyreliably. - Execute any operation after
Account_Destroybut beforeAccount_GetBalancethat allows us to allocate a reasonable amount of memory, with contents of our choosing.
Usually, these calls are triggered in different places, so it’s not too difficult to achieve this. Now, here’s what happens:
Account_Createallocates an 8-byte block of memory (4 bytes for each field) and returns a pointer to it. This pointer is now stored in themyAccountvariable.Account_Destroyfrees the memory. ThemyAccountvariable still points to the same memory address.- We trigger our memory allocation, containing repeating blocks of
39 05 00 00 01 00 00 00. This pattern correlates tobalance = 1337andtransactionCount = 1. Since the old memory block is now marked as free, it is very likely that the memory manager will write our new memory over the old memory block. Account_GetBalanceis called, expecting to point to anAccountstruct. In actuality, it points to our overwritten memory block, resulting in our balance actually being 1337, so the loan is approved!
This is all a simplification, of course, and real classes create rather more obtuse and complex code. The point is that a class instance is really just a pointer to a block of data, and class methods are just the same as any other function, but they “silently” accept a pointer to the instance as a parameter.
This principle can be extended to control values on the stack, which in turn causes program execution to be modified. Usually, the goal is to drop shellcode on the stack, then overwrite a return address such that it now points to a jmp esp instruction, which then runs the shellcode.
This trick works on non-DEP machines, but when DEP is enabled it prevents execution of the stack. Instead, the shellcode must be designed using Return-Oriented Programming (ROP), which uses small blocks of legitimate code from the application and its modules to perform an API call, in order to bypass DEP.
Anyway, I’m going off-topic a bit, so let’s get into the juicy details of CVE-2012-4969!
In the wild, the payload was dropped via a packed Flash file, designed to exploit the Java vulnerability and the new IE bug in one go. There’s also been some interesting analysis of it by AlienVault.
The metasploit module says the following:
> This module exploits a vulnerability found in Microsoft Internet Explorer (MSIE). When rendering an HTML page, the CMshtmlEd object gets deleted in an unexpected manner, but the same memory is reused again later in the CMshtmlEd::Exec() function, leading to a use-after-free condition.
There’s also an interesting blog post about the bug, albeit in rather poor English – I believe the author is Chinese. Anyway, the blog post goes into some detail:
> When the execCommand function of IE execute a command event, will allocated the corresponding CMshtmlEd object by AddCommandTarget function, and then call mshtml@CMshtmlEd::Exec() function execution. But, after the execCommand function to add the corresponding event, will immediately trigger and call the corresponding event function. Through the document.write("L") function to rewrite html in the corresponding event function be called. Thereby lead IE call CHTMLEditor::DeleteCommandTarget to release the original applied object of CMshtmlEd, and then cause triggered the used-after-free vulnerability when behind execute the msheml!CMshtmlEd::Exec() function.
Let’s see if we can parse that into something a little more readable:
- An event is applied to an element in the document.
- The event executes, via
execCommand, which allocates aCMshtmlEdobject via theAddCommandTargetfunction. - The target event uses
document.writeto modify the page. - The event is no longer needed, so the
CMshtmlEdobject is freed viaCHTMLEditor::DeleteCommandTarget. execCommandlater callsCMshtmlEd::Exec()on that object, after it has been freed.
Part of the code at the crash site looks like this:
637d464e 8b07 mov eax,dword ptr [edi] 637d4650 57 push edi 637d4651 ff5008 call dword ptr [eax+8]The use-after-free allows the attacker to control the value of
edi, which can be modified to point at memory that the attacker controls. Let’s say that we can insert arbitrary code into memory at 01234f00, via a memory allocation. We populate the data as follows:
01234f00: 01234f08 01234f04: 41414141 01234f08: 01234f0a 01234f0a: c3c3c3c3 // int3 breakpoint1. We set
edi to 01234f00, via the use-after-free bug.
2. mov eax,dword ptr [edi] results in eax being populated with the memory at the address in edi, i.e. 01234f00.
3. push edi pushes 01234f00 to the stack.
4. call dword ptr [eax+8] takes eax (which is 01234f00) and adds 8 to it, giving us 01234f08. It then dereferences that memory address, giving us 01234f0a. Finally, it calls 01234f0a.
5. The data at 01234f0a is treated as an instruction. c3 translates to an int3, which causes the debugger to raise a breakpoint. We’ve executed code!
This allows us to control eip, so we can modify program flow to our own shellcode, or to a ROP chain.
Please keep in mind that the above is just an example, and in reality there are many other challenges in exploiting this bug. It’s a pretty standard use-after-free, but the nature of JavaScript makes for some interesting timing and heap-spraying tricks, and DEP forces us to use ROP to gain an executable memory block.
Liked this question of the week? Interested in reading it or adding an answer? See the question in full. Have questions of a security nature of your own? Security expert and want to help others? Come and join us at security.stackexchange.com.
Security Stack Exchange’s first anniversary competition – results!
To celebrate our first anniversary since graduation as a fully fledged Stack Exchange site, we recently held a four week competition with prizes for individuals in the community who suggest useful edits, provide high scoring questions or answers, and for those who resurrect unloved questions to allow them to be answered successfully.
These prizes are arranged into three levels (details over on the competition post) with some delicious prizes supplied by the team at Stack Exchange headquarters:
Level 1 prizes are the much sought after Security Stack Exchange T-Shirt – here modelled by community moderator Jeff Ferland:
and in closer detail:

Andrey Botalov, Zuly Gonzales, x711Li, queso, tylerl, jao and I will be getting one of these!
Level 2 prizes are Corsair Flash Survivor USB drives. Shiny, waterproof, rock solid:

StupidOne, dgarcia, D.W. and Lucas Kauffman each earned a Survivor!
and the top prize is a WiFi Pineapple from the hak5 group:

Polynomial – we’ll be expecting blog posts on exactly what you get up to with this baby!
Congratulations to all our winners – we will get prizes off to you as soon as we can!
I wonder what we will do next year – suggestions gratefully welcomed!
How can you protect yourself from CRIME, BEAST’s successor?
For those who haven’t been following Juliano Rizzo and Thai Duong, two researchers who developed the BEAST attack against TLS 1.0/SSL 3.0 in September 2011, they have developed another attack they plan to publish at the Ekoparty conference in Argentina later this month – this time giving them the ability to hijack HTTPS sessions – and this has started people worrying again.
Security Stack Exchange member Kyle Rozendo asked this question:
With the advent of CRIME, BEASTs successor, what is possible protection is available for an individual and / or system owner in order to protect themselves and their users against this new attack on TLS?
And the community expectation was that we wouldn’t get an answer until Rizzo and Duong presented their attack.
However, our highest reputation member, Thomas Pornin delivered this awesome hypothesis, which I will quote here verbatim:
This attack is supposed to be presented in 10 days from now, but my guess is that they use compression.
SSL/TLS optionally supports data compression. In the ClientHello message, the client states the list of compression algorithms that it knows of, and the server responds, in the ServerHello, with the compression algorithm that will be used. Compression algorithms are specified by one-byte identifiers, and TLS 1.2 (RFC 5246) defines only the null compression method (i.e. no compression at all). Other documents specify compression methods, in particular RFC 3749 which defines compression method 1, based on DEFLATE, the LZ77-derivative which is at the core of the GZip format and also modern Zip archives. When compression is used, it is applied on all the transferred data, as a long stream. In particular, when used with HTTPS, compression is applied on all the successive HTTP requests in the stream, header included. DEFLATE works by locating repeated subsequences of bytes.
Suppose that the attacker is some Javascript code which can send arbitrary requests to a target site (e.g. a bank) and runs on the attacked machine; the browser will send these requests with the user’s cookie for that bank — the cookie value that the attacker is after. Also, let’s suppose that the attacker can observe the traffic between the user’s machine and the bank (plausibly, the attacker has access to the same LAN of WiFi hotspot than the victim; or he has hijacked a router somewhere on the path, possibly close to the bank server).
For this example, we suppose that the cookie in each HTTP request looks like this:
> Cookie: secret=7xc89f+94/wa
The attacker knows the “Cookie: secret=” part and wishes to obtain the secret value. So he instructs his Javascript code to issue a request containing in the body the sequence “Cookie: secret=0”. The HTTP request will look like this:
POST / HTTP/1.1 Host: thebankserver.com (…) Cookie: secret=7xc89f+94/wa (…)
Cookie: secret=0
When DEFLATE sees that, it will recognize the repeated “Cookie: secret=” sequence and represent the second instance with a very short token (one which states “previous sequence has length 15 and was located n bytes in the past); DEFLATE will have to emit an extra token for the ‘0’.
The request goes to the server. From the outside, the eavesdropping part of the attacker sees an opaque blob (SSL encrypts the data) but he can see the blob length (with byte granularity when the connection uses RC4; with block ciphers there is a bit of padding, but the attacker can adjust the contents of his requests so that he may phase with block boundaries, so, in practice, the attacker can know the length of the compressed request).
Now, the attacker tries again, with “Cookie: secret=1” in the request body. Then, “Cookie: secret=2”, and so on. All these requests will compress to the same size (almost — there are subtleties with Huffman codes as used in DEFLATE), except the one which contains “Cookie: secret=7”, which compresses better (16 bytes of repeated subsequence instead of 15), and thus will be shorter. The attacker sees that. Therefore, in a few dozen requests, the attacker has guessed the first byte of the secret value.
He then just has to repeat the process (“Cookie: secret=70”, “Cookie: secret=71”, and so on) and obtain, byte by byte, the complete secret.
What I describe above is what I thought of when I read the article, which talks about “information leak” from an “optional feature”. I cannot know for sure that what will be published as the CRIME attack is really based upon compression. However, I do not see how the attack on compression cannot work. Therefore, regardless of whether CRIME turns out to abuse compression or be something completely different, you should turn off compression support from your client (or your server).
Note that I am talking about compression at the SSL level. HTTP also includes optional compression, but this one applies only to the body of the requests and responses, not the header, and thus does not cover the Cookie: header line. HTTP-level compression is fine.
(It is a shame to have to remove SSL compression, because it is very useful to lower bandwidth requirements, especially when a site contains many small pictures or is Ajax-heavy with many small requests, all beginning with extremely similar versions of a mammoth HTTP header. It would be better if the security model of Javascript was fixed to prevent malicious code from sending arbitrary requests to a bank server; I am not sure it is easy, though.)
As bobince commented:
I hope CRIME is this and we don’t have two vulns of this size in play! However, I wouldn’t say that being limited to entity bodies makes HTTP-level compression safe in general… whilst a cookie header is an obvious first choice of attack, there is potentially sensitive material in the body too. eg Imagine sniffing an anti-XSRF token from response body by causing the browser to send fields that get reflected in that response.
It is reassuring that there is a fix, and my recommendation would be for everyone to assess the risk to them of having sessions hijacked and seriously consider disabling SSL compression support.